Migrate OSDs from one storage class to another
In this article, I’ll explain how to migrate your OpenShift Data Foundation OSDs (disks), residing on one cloud storage class, for example Azure managed-premium, to another storage class, for example Azure managed-csi, this will be a “rolling” migration, with no service and data interruption.
Warning: If you are a Red Hat customer, open a support case before going forward, otherwise doing the following steps at your own risk!
Requirements
Before starting you’ll need:
- installed and working OpenShift Data Foundation;
- configured new / destination Storage Class => in this article I’ll use managed-csi;
- ODF configured with replica parameter set to 3[0];
- in this guide I’ll move data / disks, only from 3 OSD disks to other 3 OSD disks, in different storage classes, if you have more than 3 OSD you have to redo this procedure from start to finish.
[0] In this guide I’ll assume your OpenShift Data Foundation is installed on the hyperscaler cloud provider, for example Azure or AWS, with 3 availability zones, and with this configuration you should have replica set to 3:
$ oc get storagecluster -n openshift-storage ocs-storagecluster -ojson | jq .spec.storageDeviceSets
[
{
"count": 1,
...
"replica": 3,
...
}
]
Run must-gather
Before applying any change run an OpenShift must-gather:
$ oc adm must-gather
then, create a specific ODF must-gather, in this example I use ODF in version 4.10:
$ mkdir ~/odf-must-gather
$ oc adm must-gather --image=registry.redhat.io/odf4/ocs-must-gather-rhel8:v4.10 --dest-dir=~/odf-must-gather
Check cluster health
Check if your cluster is healthy:
$ NAMESPACE=openshift-storage;ROOK_POD=$(oc -n ${NAMESPACE} get pod -l app=rook-ceph-operator -o jsonpath='{.items[0].metadata.name}');oc exec -it ${ROOK_POD} -n ${NAMESPACE} -- ceph status --cluster=${NAMESPACE} --conf=/var/lib/rook/${NAMESPACE}/${NAMESPACE}.config --keyring=/var/lib/rook/${NAMESPACE}/client.admin.keyring | grep HEALTH
health: HEALTH_OK
WARNING: if your cluster is not in HEALTH_OK, stop any activities and check first ODF state!
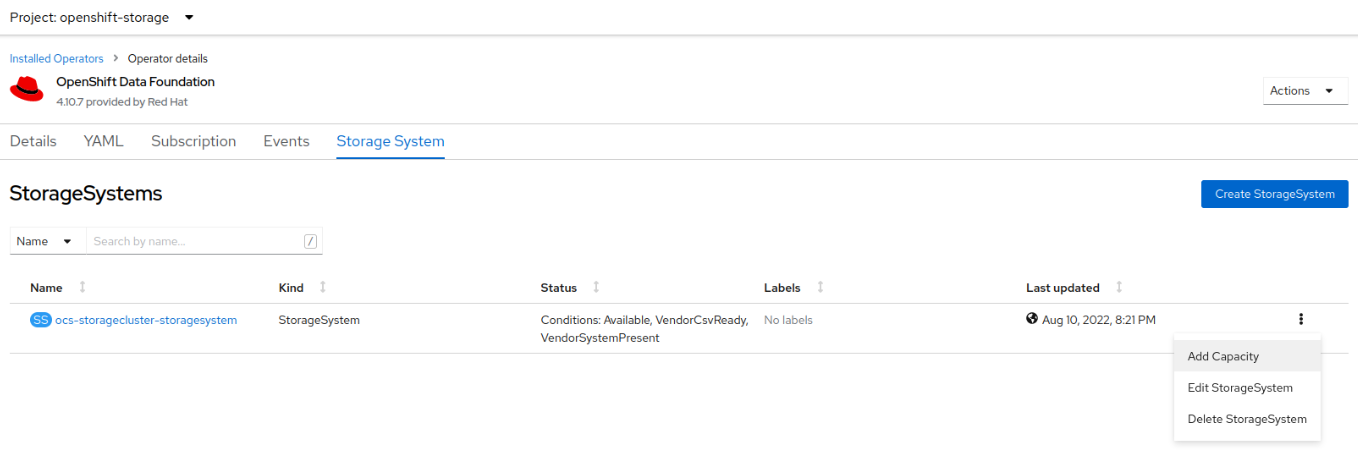
Add Capacity
Add new capacity to your cluster using new StorageClass, in my case managed-csi navigating to:
- select Left menu Operators => Installed Operators => OpenShift Data Foundation (selecting project openshift-storage on left corner);
- select “Storage System” tab;
- click on the three dot on the right and then select Add Capacity
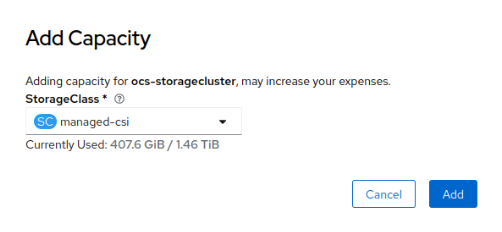
- select your desired storage class and then click Add
wait until ODF will rebalance all data, which means cluster will be in HEALTH_OK status and all placement groups (pgs) must be in active+clean state, to monitor rebalance you can use a while true infinite loop:
$ while true; do NAMESPACE=openshift-storage;ROOK_POD=$(oc -n ${NAMESPACE} get pod -l app=rook-ceph-operator -o jsonpath='{.items[0].metadata.name}');oc exec -it ${ROOK_POD} -n ${NAMESPACE} -- ceph status --cluster=${NAMESPACE} --conf=/var/lib/rook/${NAMESPACE}/${NAMESPACE}.config --keyring=/var/lib/rook/${NAMESPACE}/client.admin.keyring | egrep 'HEALTH_OK|HEALTH_WARN|[0-9]+\s+remapped|[0-9]+\/[0-9]+[ a-z]+misplaced[ ().%a-z0-9]+|' ; sleep 10 ; done
cluster:
id: ....
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 4d)
mgr: a(active, since 4d)
mds: 1/1 daemons up, 1 hot standby
osd: 6 osds: 6 up (since 6m), 6 in (since 6m); 135 remapped pgs
data:
volumes: 1/1 healthy
pools: 4 pools, 193 pgs
objects: 13.34k objects, 49 GiB
usage: 147 GiB used, 2.8 TiB / 2.9 TiB avail
pgs: 17928/40008 objects misplaced (44.811%)
134 active+remapped+backfill_wait
58 active+clean
1 active+remapped+backfilling
io:
client: 4.8 KiB/s rd, 328 KiB/s wr, 2 op/s rd, 5 op/s wr
recovery: 13 MiB/s, 3 objects/s
progress:
Global Recovery Event (6m)
[========....................] (remaining: 14m)
in the above example, you can see that ceph is rebalancing / remapping PGs, wait until all PGs are in active+clean state:
$ NAMESPACE=openshift-storage;ROOK_POD=$(oc -n ${NAMESPACE} get pod -l app=rook-ceph-operator -o jsonpath='{.items[0].metadata.name}');oc exec -it ${ROOK_POD} -n ${NAMESPACE} -- ceph status --cluster=${NAMESPACE} --conf=/var/lib/rook/${NAMESPACE}/${NAMESPACE}.config --keyring=/var/lib/rook/${NAMESPACE}/client.admin.keyring
cluster:
id: ....
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 2d)
mgr: a(active, since 2d)
mds: 1/1 daemons up, 1 hot standby
osd: 6 osds: 6 up (since 105m), 6 in (since 106m)
data:
volumes: 1/1 healthy
pools: 4 pools, 193 pgs
objects: 45.33k objects, 73 GiB
usage: 223 GiB used, 2.7 TiB / 2.9 TiB avail
pgs: 193 active+clean
io:
client: 82 KiB/s rd, 12 MiB/s wr, 3 op/s rd, 113 op/s wr
WARNING: wait until your cluster returns all PGs in active+clean state!
check also CephFS status:
$ NAMESPACE=openshift-storage;ROOK_POD=$(oc -n ${NAMESPACE} get pod -l app=rook-ceph-operator -o jsonpath='{.items[0].metadata.name}');oc exec -it ${ROOK_POD} -n ${NAMESPACE} -- ceph fs status --cluster=${NAMESPACE} --conf=/var/lib/rook/${NAMESPACE}/${NAMESPACE}.config --keyring=/var/lib/rook/${NAMESPACE}/client.admin.keyring
ocs-storagecluster-cephfilesystem - 12 clients
=================================
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ocs-storagecluster-cephfilesystem-b Reqs: 37 /s 34.8k 27.2k 8369 27.1k
0-s standby-replay ocs-storagecluster-cephfilesystem-a Evts: 47 /s 82.3k 26.8k 8298 0
POOL TYPE USED AVAIL
ocs-storagecluster-cephfilesystem-metadata metadata 758M 697G
ocs-storagecluster-cephfilesystem-data0 data 212G 697G
MDS version: ceph version 16.2.7-126.el8cp (fe0af61d104d48cb9d116cde6e593b5fc8c197e4) pacific (stable)
WARNING: one of the two MDS must be in active state!
Identify old OSDs / disks to remove
Take a note of your 3 OSD id to remove, they are based on your old StorageClass, to see ODF OSD topology run:
$ NAMESPACE=openshift-storage;ROOK_POD=$(oc -n ${NAMESPACE} get pod -l app=rook-ceph-operator -o jsonpath='{.items[0].metadata.name}');oc exec -it ${ROOK_POD} -n ${NAMESPACE} -- ceph osd tree --cluster=${NAMESPACE} --conf=/var/lib/rook/${NAMESPACE}/${NAMESPACE}.config --keyring=/var/lib/rook/${NAMESPACE}/client.admin.keyring
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.92978 root default
-5 2.92978 region westeurope
-14 0.97659 zone westeurope-1
-13 0.48830 host clustername-ocs-westeurope1-qpdqh
2 hdd 0.48830 osd.2 up 1.00000 1.00000
-17 0.48830 host ocs-deviceset-managed-csi-1-data-0tfdrp
3 hdd 0.48830 osd.3 up 1.00000 1.00000
-10 0.97659 zone westeurope-2
-9 0.48830 host clustername-ocs-westeurope2-46789
1 hdd 0.48830 osd.1 up 1.00000 1.00000
-19 0.48830 host ocs-deviceset-managed-csi-0-data-0zzxzr
4 hdd 0.48830 osd.4 up 1.00000 1.00000
-4 0.97659 zone westeurope-3
-3 0.48830 host clustername-ocs-westeurope3-9wsjs
0 hdd 0.48830 osd.0 up 1.00000 1.00000
-21 0.48830 host ocs-deviceset-managed-csi-2-data-0bc889
5 hdd 0.48830 osd.5 up 1.00000 1.00000
In my case the old OSD are osd.0, osd.1 and osd.2, those OSDs needs to be removed / deleted one by one, waiting for HEALTH_OK after every removing / deleting.
Remove OSD in old StorageClass
Switch to openshift-storage project
First switch to openshift-storage project:
$ oc project openshift-storage
Copy Ceph config and keyring files
Copy your Ceph config file and keyring file from rook container pod to your Linux box, then those files will be transferred to one mon container in order to run ceph commands after scaling down rook operator.
Copy files from rook container to your Linux box:
$ ROOK=$(oc get pod | grep rook-ceph-operator | awk '{print $1}')
$ oc rsync ${ROOK}:/var/lib/rook/openshift-storage/openshift-storage.config .
WARNING: cannot use rsync: rsync not available in container
openshift-storage.config
$ oc rsync ${ROOK}:/var/lib/rook/openshift-storage/client.admin.keyring .
WARNING: cannot use rsync: rsync not available in container
client.admin.keyring
Copy openshift-storage.config and openshift-storage.config files from your Linux box to one mon container:
$ MONA=$(oc get pod | grep rook-ceph-mon | egrep '2\/2\s+Running' | head -n1 | awk '{print $1}')
$ oc cp openshift-storage.config ${MONA}:/tmp/openshift-storage.config
Defaulted container "mon" out of: mon, log-collector, chown-container-data-dir (init), init-mon-fs (init)
$ oc cp client.admin.keyring ${MONA}:/tmp/client.admin.keyring
Defaulted container "mon" out of: mon, log-collector, chown-container-data-dir (init), init-mon-fs (init)
NOTE: MONA, in one of Italian regional language means stupid people ![]()
Check ceph command on MONA container:
$ oc rsh ${MONA}
Defaulted container "mon" out of: mon, log-collector, chown-container-data-dir (init), init-mon-fs (init)
sh-4.4# ceph health --cluster=openshift-storage --conf=/tmp/openshift-storage.config --keyring=/tmp/client.admin.keyring
2022-XX -1 auth: unable to find a keyring on /var/lib/rook/openshift-storage/client.admin.keyring: (2) No such file or directory
2022-XX -1 AuthRegistry(0x7fa63805bb68) no keyring found at /var/lib/rook/openshift-storage/client.admin.keyring, disabling cephx
HEALTH_OK
sh-4.4#
Scale down OpenShift Data Foundation operators
Now we can scale to zero rook and ocs operators:
$ oc scale deploy ocs-operator --replicas=0
deployment.apps/ocs-operator scaled
$ oc scale deploy rook-ceph-operator --replicas=0
deployment.apps/rook-ceph-operator scaled
Remove one OSD
Now you can remove one OSD, in my case I’ll remove osd.0 (zero), but in your case could be a different ID.
$ failed_osd_id=0
$ export PS1="[\u@\h \W]\ OSD=$failed_osd_id $ "
$ oc scale deploy rook-ceph-osd-${failed_osd_id} --replicas=0
deployment.apps/rook-ceph-osd-0 scaled
$ oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_IDS=${failed_osd_id} | oc create -f -
job.batch/ocs-osd-removal-job created
$ JOBREMOVAL=$(oc get pod | grep ocs-osd-removal-job- | awk '{print $1}')
$ oc logs ${JOBREMOVAL} | egrep "cephosd: completed removal of OSD ${failed_osd_id}"
2022-XX I | cephosd: completed removal of OSD 0
NOTE: on the last command you must see cephosd: completed removal of OSD X, where X is your osd id (in my case zero).
check ceph health status, where you can see a degraded state due to one osd removal:
$ oc rsh ${MONA}
Defaulted container "mon" out of: mon, log-collector, chown-container-data-dir (init), init-mon-fs (init)
sh-4.4# ceph status --cluster=openshift-storage --conf=/tmp/openshift-storage.config --keyring=/tmp/client.admin.keyring
cluster:
id: ....
health: HEALTH_WARN
Degraded data redundancy: 19562/138537 objects degraded (14.120%), 96 pgs degraded, 96 pgs undersized
services:
mon: 3 daemons, quorum a,b,c (age 2d)
mgr: a(active, since 2d)
mds: 1/1 daemons up, 1 hot standby
osd: 5 osds: 5 up (since 6m), 5 in (since 3m); 110 remapped pgs
data:
volumes: 1/1 healthy
pools: 4 pools, 193 pgs
objects: 46.18k objects, 73 GiB
usage: 192 GiB used, 2.3 TiB / 2.4 TiB avail
pgs: 19562/138537 objects degraded (14.120%)
6098/138537 objects misplaced (4.402%)
95 active+undersized+degraded+remapped+backfill_wait
83 active+clean
14 active+remapped+backfill_wait
1 active+undersized+degraded+remapped+backfilling
io:
client: 131 KiB/s rd, 14 MiB/s wr, 4 op/s rd, 151 op/s wr
recovery: 1023 KiB/s, 14 keys/s, 7 objects/s
sh-4.4#
wait until ceph returns HEALTH_OK and all PGs are active+clean:
sh-4.4# while true; do ceph status --cluster=openshift-storage --conf=/tmp/openshift-storage.config --keyring=/tmp/client.admin.keyring | egrep --color=always '[0-9]+\/[0-9]+.*(degraded|misplaced)|' ; sleep 10 ; done
cluster:
id: ....
health: HEALTH_WARN
Degraded data redundancy: 17957/136521 objects degraded (13.153%), 91 pgs degraded, 91 pgs undersized
services:
mon: 3 daemons, quorum a,b,c (age 2d)
mgr: a(active, since 2d)
mds: 1/1 daemons up, 1 hot standby
osd: 5 osds: 5 up (since 8m), 5 in (since 6m); 105 remapped pgs
data:
volumes: 1/1 healthy
pools: 4 pools, 193 pgs
objects: 45.51k objects, 73 GiB
usage: 194 GiB used, 2.3 TiB / 2.4 TiB avail
pgs: 17957/136521 objects degraded (13.153%)
5767/136521 objects misplaced (4.224%)
90 active+undersized+degraded+remapped+backfill_wait
88 active+clean
14 active+remapped+backfill_wait
1 active+undersized+degraded+remapped+backfilling
io:
client: 90 KiB/s rd, 14 MiB/s wr, 2 op/s rd, 145 op/s wr
recovery: 1023 KiB/s, 20 keys/s, 10 objects/s
...... (cut)
cluster:
id: ....
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 2d)
mgr: a(active, since 2d)
mds: 1/1 daemons up, 1 hot standby
osd: 5 osds: 5 up (since 61m), 5 in (since 58m)
data:
volumes: 1/1 healthy
pools: 4 pools, 193 pgs
objects: 45.63k objects, 74 GiB
usage: 226 GiB used, 2.2 TiB / 2.4 TiB avail
pgs: 193 active+clean
io:
client: 115 KiB/s rd, 14 MiB/s wr, 4 op/s rd, 139 op/s wr
WARNING: before going forward you must wait for ceph HEALTH_OK and all PGs in active+clean state!
Delete removal job:
$ oc delete job ocs-osd-removal-job
job.batch "ocs-osd-removal-job" deleted
Repeat these steps for each OSD you need to remove (in my case for osd.1 and osd.2)
Remove your old storage class
After removing all OSD that belongs to your old storageclass (in my case Azure managed-premium), you can edit your storagecluster object to remove any pointer to the old storage class.
Make a backup before editing your storagecluster:
$ oc get storagecluster ocs-storagecluster -oyaml | tee storagecluster-ocs-storagecluster-before-remove-managed-premium.yaml
change / edit your storagecluster storageDeviceSets, from having OSD from both “old” storageclass (in my case managed-premium) and “new” storageclass (in my case managed-csi):
$ oc get storagecluster ocs-storagecluster -oyaml
....
storageDeviceSets:
- config: {}
count: 1
dataPVCTemplate:
metadata: {}
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Gi
storageClassName: managed-premium
volumeMode: Block
status: {}
name: ocs-deviceset
placement: {}
preparePlacement: {}
replica: 3
resources:
limits:
cpu: "2"
memory: 5Gi
requests:
cpu: "2"
memory: 5Gi
- count: 1
dataPVCTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Gi
storageClassName: managed-csi
volumeMode: Block
name: ocs-deviceset-managed-csi
placement: {}
portable: true
replica: 3
resources: {}
to have only “new” storageclass (in my case managed-csi):
$ oc edit storagecluster ocs-storagecluster
....
storageDeviceSets:
- count: 1
dataPVCTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Gi
storageClassName: managed-csi
volumeMode: Block
name: ocs-deviceset-managed-csi
placement: {}
portable: true
replica: 3
resources:
limits:
cpu: "2"
memory: 5Gi
requests:
cpu: "2"
memory: 5Gi
Scale up OpenShift Data Foundation operators
At this point you can scale up ocs-operator:
$ oc scale deploy ocs-operator --replicas=1
deployment.apps/ocs-operator scaled
and then re-check Ceph health status:
$ NAMESPACE=openshift-storage;ROOK_POD=$(oc -n ${NAMESPACE} get pod -l app=rook-ceph-operator -o jsonpath='{.items[0].metadata.name}');oc exec -it ${ROOK_POD} -n ${NAMESPACE} -- ceph status --cluster=${NAMESPACE} --conf=/var/lib/rook/${NAMESPACE}/${NAMESPACE}.config --keyring=/var/lib/rook/${NAMESPACE}/client.admin.keyring | egrep -i 'remapped|misplaced|active\+clean|HEALTH_OK|'
cluster:
id: ....
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 3d)
mgr: a(active, since 3d)
mds: 1/1 daemons up, 1 hot standby
osd: 3 osds: 3 up (since 2h), 3 in (since 2h)
data:
volumes: 1/1 healthy
pools: 4 pools, 193 pgs
objects: 45.87k objects, 74 GiB
usage: 226 GiB used, 1.2 TiB / 1.5 TiB avail
pgs: 193 active+clean
io:
client: 134 KiB/s rd, 60 MiB/s wr, 4 op/s rd, 322 op/s wr