Planning a trip to Perú with an LLM wiki
Planning a long, multi-city trip is, at its core, a knowledge management problem. Over the weeks before departure you accumulate a pile of heterogeneous sources – a guidebook PDF, a dozen blog posts, restaurant lists, official site maps, booking confirmations – and they end up scattered across browser tabs, screenshots, and half-finished notes. Every time you need an answer (“how do we get from A to B?”, “is this restaurant safe for me?”) you re-read the same sources from scratch. The knowledge never compounds.
When Andrej Karpathy published his LLM wiki pattern in April 2026, it struck me as the right tool for exactly this kind of problem. So I used it to plan a two-week trip across Perú – Lima, Arequipa, Cuzco and the Sacred Valley, Machu Picchu, and Lake Titicaca – and then carried the result with me on the ground. This post is about how I did it: the structure, the schema, the workflows, and the laptop-to-mobile loop that made it useful during the trip and not just before it.
The LLM wiki pattern in 60 seconds
Karpathy’s idea is a reaction to the “throw your PDFs into a chat window and hope for the best” approach. Instead of running retrieval over raw documents every single time, you have an LLM agent incrementally build and maintain a structured wiki of markdown files. The knowledge base becomes a first-class artifact that grows, gets cross-referenced, and stays consistent over time.
The pattern is built on three layers:
- Raw sources (
raw/) – articles, papers, PDFs, maps. These are immutable: the agent reads from them but never modifies them. This is your source of truth. - The wiki (
wiki/) – a directory of LLM-generated markdown: entity pages, concept pages, comparisons, an index, filed answers. The agent owns this layer entirely. It creates pages, updates them when new sources arrive, and maintains the cross-links. - The schema – a document (
CLAUDE.mdfor Claude Code,AGENTS.mdfor other agents) that tells the LLM how the wiki is organized, what the conventions are, and which workflows to follow.
The schema is the part that makes the whole thing work. It is, in effect, the constitution of your knowledge base.
Why trip planning is a perfect fit
A few properties of trip planning make it an ideal first project for this pattern:
- It accumulates over time. You don’t ingest everything at once; sources trickle in over weeks.
- It is full of entities and relations. Cities, archaeological sites, regions, hotels, dishes, logistics – and they are densely connected (a city is the base for several day-trips, a region contains several sites, a concept like altitude sickness touches almost everything).
- It evolves as reality firms up. Bookings get locked, plans get recalibrated, and the wiki has to keep up.
- It has a clear “field” phase. Eventually the plan meets the ground, and reality has notes of its own.
That last point is what convinced me. Most knowledge bases are read-only once built. A trip wiki has a feedback loop: you plan, you travel, and what you learn flows back in.
My setup
The stack was deliberately boring:
- Claude Code as the agent that reads sources and writes the wiki.
- Obsidian to read and visualize the wiki – it’s just markdown with
[[wikilinks]], so Obsidian gives you the graph for free. - git for history – one commit per logical operation, so I can always see how the wiki evolved.
The wiki/ directory is organized by entity type. A trimmed view of the taxonomy:
peru-llm-wiki/
├── raw/ # read-only sources (guidebook PDF, maps, docs)
├── wiki/
│ ├── index.md # catalogue of every page, maintained by the agent
│ ├── log.md # append-only log of every ingest / query / lint
│ ├── cities/ # lima, arequipa, cuzco, puno, ...
│ ├── sites/ # machu-picchu, saqsaywaman, islas-uros, ...
│ ├── regions/ # sacred-valley, lake-titicaca
│ ├── logistics/ # hotels, transport, insurance
│ ├── food/ # cuisine overview, picanterías, pisco
│ ├── concepts/ # soroche (altitude sickness), boleto-turístico
│ └── queries/ # filed answers: day-by-day operational plans
└── CLAUDE.md # the schema
By the end the wiki was around 46 pages.
The schema is the heart of it
Everything good about this project came from spending real effort on CLAUDE.md before ingesting a single source. Here are the parts that earned their keep (translated to English here; in my actual file the conventions are written in the same mixed style the wiki uses).
The three layers, stated as rules the agent cannot break:
## Three layers
- raw/ — READ-ONLY for you. Immutable sources. Never modify.
- wiki/ — OWN ENTIRELY. You create, update, reorganize. I read and give direction.
- CLAUDE.md — this file. Changes only after my explicit confirmation.
Language conventions. This is a small detail that paid off enormously. Filenames, paths, wikilinks and frontmatter keys are always English kebab-case, while page bodies are in my own language and direct quotes keep their original language. That keeps the structure stable and machine-friendly while the content stays natural to read:
- Filenames / paths / wikilinks: English, kebab-case → cities/cuzco.md, [[machu-picchu]]
- Entity names: keep the original Spanish form when it's the de-facto name → Sacsayhuamán, soroche
- Page bodies: my notes language
- Direct quotes from sources: original language, in a blockquote, with attribution
A mandatory frontmatter on every page, so the wiki is queryable and lintable:
---
type: city | site | trek | region | logistics | food | concept | fieldnote | query
sources: [raw/pdfs/travel-guidebook.pdf, raw/docs/flights-itinerary.md]
updated: 2026-05-02
tags: [sacred-valley, altitude, must-see]
status: stub | draft | stable
---
Anti-hallucination rules. This is the single most important section. Travel planning lives and dies on accurate numbers – prices, distances, opening hours, altitudes – and an LLM that confidently invents them is worse than useless. So the schema forbids it explicitly:
- Cite the raw source with a relative path next to every non-trivial claim: (raw/docs/blog-x.md)
- Mark [unverified] any claim from a single weak or unconfirmed source
- Mark [contradicted: <page>] when you find a conflict with another page or source
- Never invent numbers (prices, distances, times). If the source doesn't give them, write [TBD]
- Admit uncertainty explicitly. [unverified] is preferable to a confident unsupported claim.
In practice the wiki is full of (raw/pdfs/travel-guidebook.pdf) citations and the occasional [unverified] or [TBD]. When two sources disagreed – for example Cuzco’s altitude listed as 3326 m in the guidebook header but commonly rounded to 3400 m elsewhere – the page records both values and explains the discrepancy instead of silently picking one.
The workflows
The rest of the schema defines a handful of named workflows. I just type the verb and the agent follows the protocol.
Ingest
ingest <source> is how knowledge enters the wiki. The agent reads the full source, summarizes it in 5–8 key points and asks for confirmation before touching the wiki, then shows me which existing pages it will update and which new ones it will create. Only after I approve does it write – one page at a time if I ask – append an entry to log.md, and update index.md.
This “summarize, confirm, then write” loop is what keeps the wiki trustworthy. I ingested a full guidebook chapter at a time and reviewed each batch of edits like a small pull request.
Query
query is where the wiki pays you back. I ask an operational question; the agent reads index.md, drills into the candidate pages, and answers with citations to both the wiki pages and the underlying raw sources. If the answer is valuable – a non-trivial synthesis, a comparison, a full day plan – it offers to file it as a page under wiki/queries/.
This is how my day-by-day itineraries were born. Here is Claude Code filing one of them – a four-day Arequipa plan – as a query page, complete with day-by-day timing, deep-links, a Mermaid map for the walking-heavy day, and a list of pre-trip open items:

Notice the last line: “Punto delicato da decidere” – the agent flags a tight connection (a walking tour starting shortly after landing with bags still in tow) and proposes a safer alternative rather than pretending the plan is risk-free. So I recalibrated it:

The recalibration is a normal conversational turn – “recalibrate the 26th without the walking tour” – and the agent rewrites that day around altitude acclimatization and a sunset anchor, then updates the log and the commit message. The plan is a living document, not a one-shot output.
Lint
lint is the maintenance pass, and it’s where a structured wiki beats a pile of notes. The agent scans for contradictions between pages, orphan pages (no incoming links), concepts mentioned but missing a page, stale claims superseded by newer sources, and malformed frontmatter. It outputs a report with proposed actions and waits for my OK before fixing anything.
Fieldnotes
This is the workflow that closes the loop. During the trip I capture raw notes on mobile as fieldnotes. The schema explicitly tells the agent not to touch them while I’m travelling – they’re mine, raw, possibly contradictory. On return I say “consolidate the fieldnotes” and the agent merges reality back into the wiki: updating entity pages with what actually happened, flagging contradictions with the pre-trip claims, and proposing new pages for themes I hadn’t anticipated. The fieldnotes themselves stay as a historical record.
Visualizing it in Obsidian
Because the wiki is plain markdown with aggressive cross-linking, Obsidian’s graph view comes for free – and it’s genuinely useful, not just pretty. The structure of the trip emerges visually: hubs (the index, the major cities), tight clusters (everything around Lake Titicaca, everything in the Sacred Valley), and the concept pages that thread through everything.
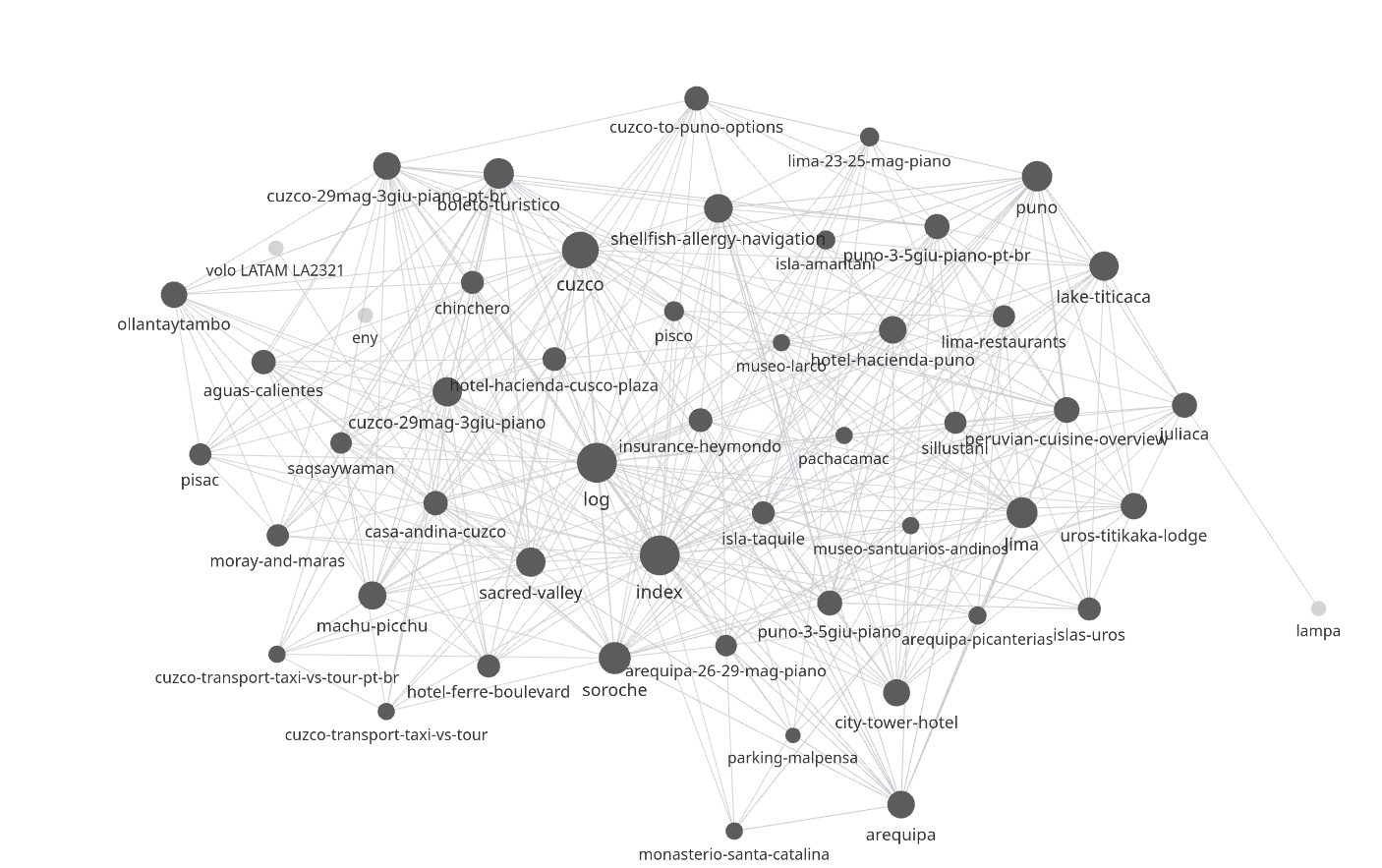
A closer, less dense view makes the hub-and-cluster structure clearer:
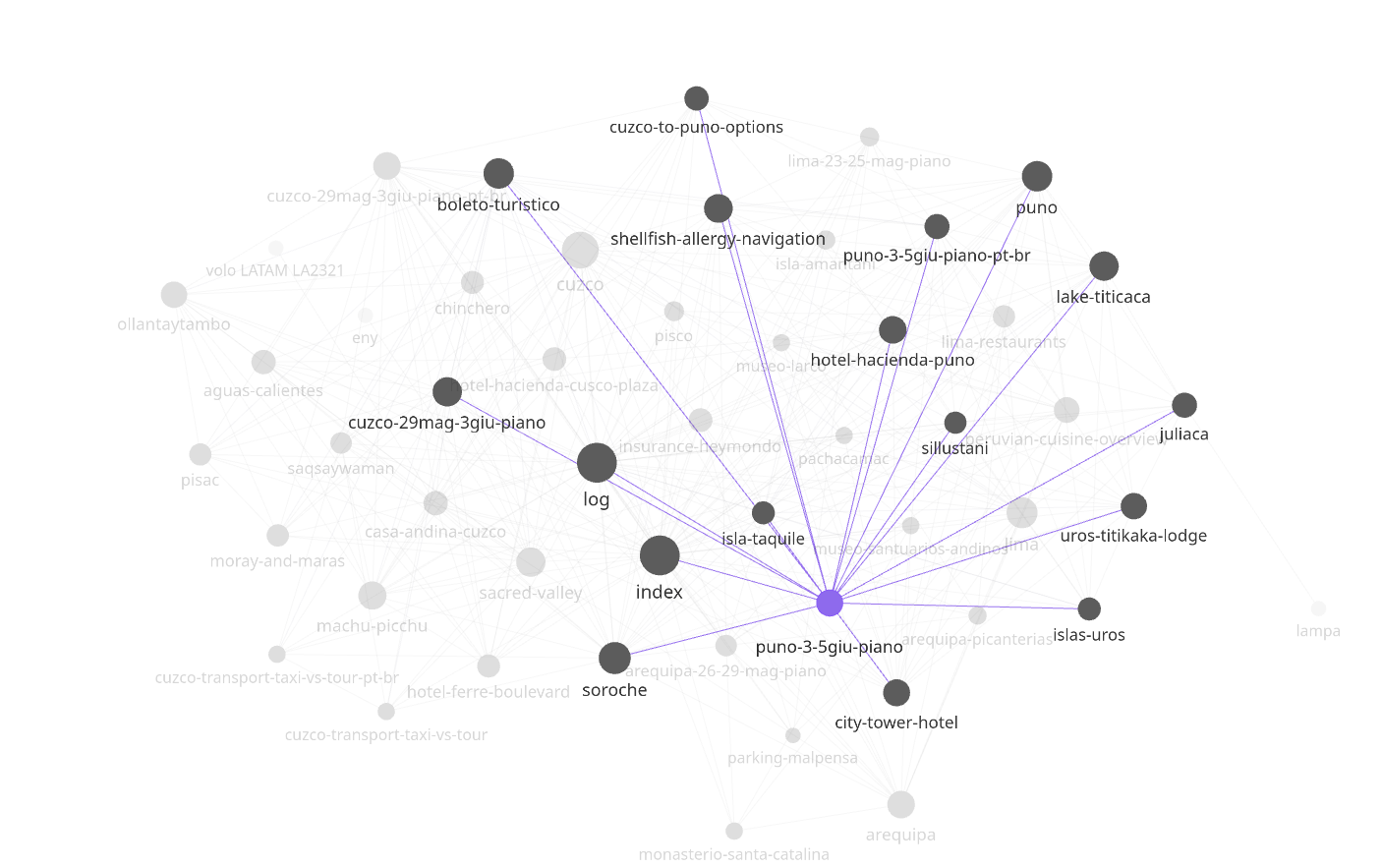
The graph is also a free lint: an orphan node jumps out immediately, and so does a cluster that should be connected but isn’t.
The field loop: laptop to mobile
A plan is only as good as your ability to use it on the ground. My loop looked like this: in the evening, back at the hotel, I refined the next day’s plan on the laptop with Claude Code – adjusting timing, swapping a restaurant, recalibrating around how tired we actually were. Then I needed that on my phone the next day.
To bridge the two I bought one month of Obsidian Sync – just for the duration of the trip. The same wiki, the same graph, in my pocket while walking around a city:

One month of Sync was a trivial cost for having the entire knowledge base – every cross-referenced page, every filed plan – available on mobile, exactly when and where I needed it.
A concrete example: navigating a food allergy
A good test of any planning system is how it handles a hard personal constraint. I’m allergic to shellfish, and Perú is one of the great seafood cuisines on the planet – ceviche, tiraditos, and cross-contamination everywhere. So the wiki has a dedicated shellfish-allergy-navigation page, and the allergy threads through the food pages and the day plans.
In practice this meant the agent annotated restaurant entries with what’s safe and why – charred octopus is a mollusc, not a crustacean, so it’s fine; a fish-only ceviche still carries cross-contamination risk, so always tell the waiter – and it folded “communicate the allergy at check-in / at the table” into the operational plans as a recurring step. You can see it surface in the Arequipa plan above as part of the day-one context. Encoding a constraint once, in a page the agent always consults, is far more reliable than remembering it restaurant by restaurant.
Takeaways
What worked:
- Front-loading the schema. Every hour spent on
CLAUDE.mdsaved many later. The anti-hallucination rules in particular are non-negotiable for anything where wrong numbers have real consequences. - “Summarize, confirm, then write.” Reviewing each ingest like a small PR kept the wiki trustworthy.
- Filed queries. Turning good answers into permanent, cross-linked pages is what makes the knowledge compound.
- The markdown-plus-Obsidian substrate. Plain files mean git history, a free graph, and trivial mobile sync.
What I’d change next time: start the fieldnotes discipline earlier and capture more of them, since the consolidation step on return was the most rewarding part.
And the pattern generalizes well beyond travel. Anything where you accumulate knowledge over time and want it organized rather than scattered – competitive analysis, due diligence, course notes, a hobby deep-dive – is a candidate. Trip planning just happens to be an unusually fun place to start, with a built-in deadline and a very tangible payoff.
If you want to try it, start from Karpathy’s original gist, write your schema first, and ingest your first source second.